实现BMP渲染器
在 从BMP分析文件二进制流 中讲了如何分析BMP文件的二进制流,本文将实际读取BMP文件并实现 BMP渲染器,采用 C++ 进行实现,GUI使用 SFML 实现窗口操作和基础渲染,刚好 SFML 本身不支持BMP的渲染,比较切合本文的主题,目前仅支持Mac系统的构建和运行,未来有时间将支持多个平台。
程序基本流程

// main.cpp
// bmp读取&解析
std::vector<u_char> buffer = readFile(filePath);
BMP bmp = bmpParser(buffer);
...
// bmp像素转SFML像素
sf::VertexArray points(sf::Points);
...
// 渲染
sf::RenderWindow window(sf::VideoMode(800, 600), "bmp viewer");
...main.cpp里面是渲染器的基本流程,首先读取对应图片数据为二进制流,使用BMP Parser对二进制流进行解析,最后转为SFML可渲染的像素集合进行渲染。
BMP Parser
BMP 文件结构
根据BMP格式详解中,可以看到BMP文件的结构如下所示
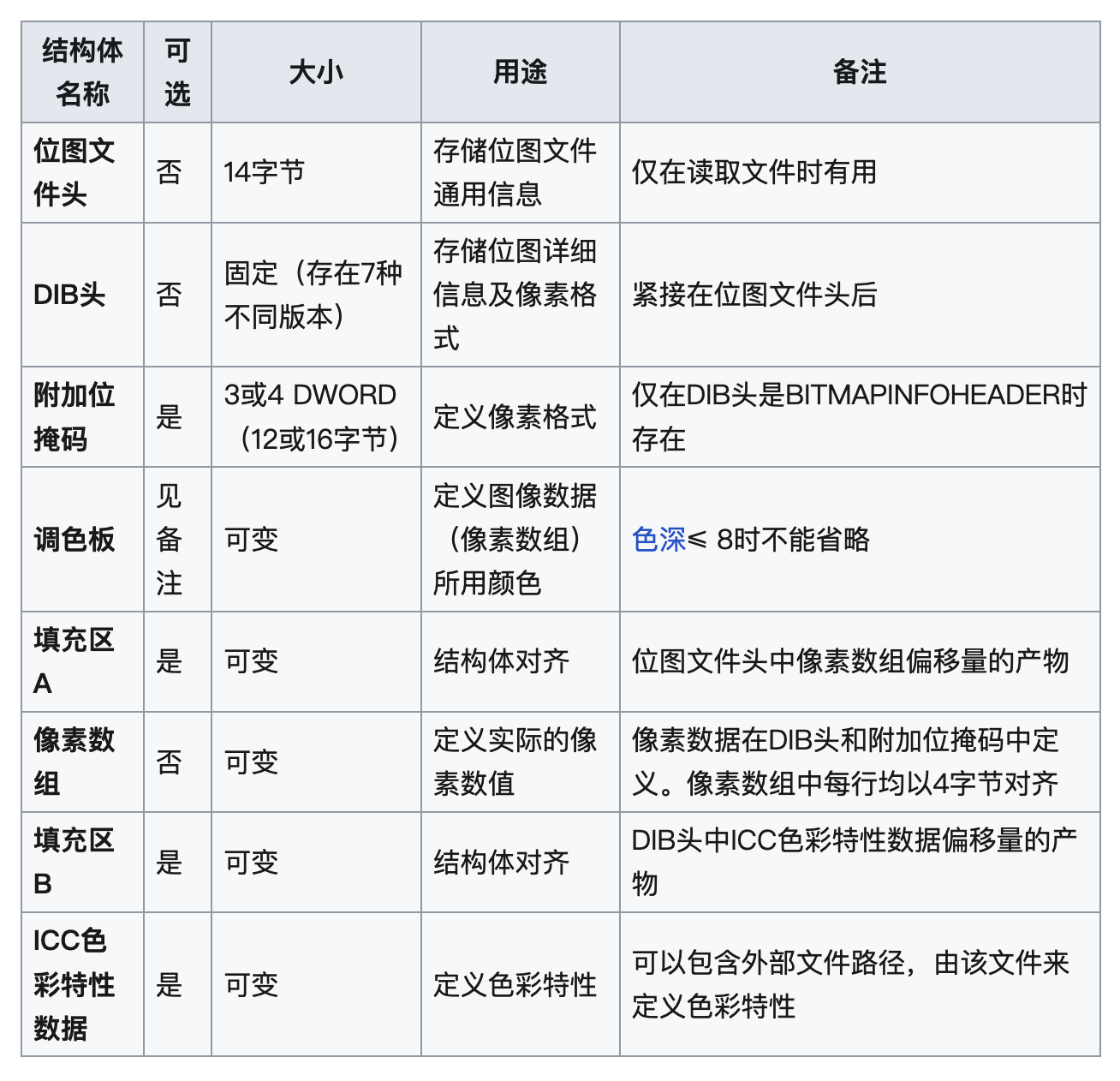
位图文件头(Bitmap file header)
- 大小:14字节
- 用途:存储BMP文件的基本信息
- 特点:必需的,加载到内存后就不再需要
DIB头(DIB header)
- 大小:固定大小(有7种不同版本)
- 用途:存储位图的详细信息和像素格式定义
- 特点:必需的,紧跟在文件头之后
额外位掩码(Extra bit masks)
- 大小:12或16字节(3-4个DWORD)
- 用途:定义像素格式
- 特点:可选的,仅在特定压缩方式下使用
调色板(Color table)
- 大小:可变
- 用途:定义位图数据使用的颜色
- 特点:半可选,在颜色深度≤8位时必需
间隙1(Gap1)
- 大小:可变
- 用途:结构对齐
- 特点:可选的,用于文件头中像素数组偏移量的对齐
像素数组(Pixel array)
- 大小:可变
- 用途:定义实际的像素值
- 特点:必需的,每行都需要按4字节对齐
间隙2(Gap2)
- 大小:可变
- 用途:结构对齐
- 特点:可选的,用于DIB头中ICC配置数据偏移量的对齐
ICC颜色配置(ICC color profile)
- 大小:可变
- 用途:定义颜色管理的配置文件
- 特点:可选的,可以包含外部文件的路径
这种结构设计使得BMP格式能够灵活地支持不同的颜色深度和图像格式,同时保持了较好的兼容性。不过这也使得BMP文件相对较大,因为它存储了未压缩的像素数据。
BMP 解析结果
// bmp_parser.hpp
struct BMP {
// 内容区起始偏移量
size_t contentStart;
// 内容区
std::vector<u_char> content;
// 压缩类型
size_t compression;
// 宽度
size_t width;
// 高度
size_t height;
// 颜色深度
size_t deep;
// 大小
size_t sizeDIB;
// 调色板
std::vector<std::vector<u_char>> palette;
// 像素集合
std::vector<std::vector<u_char>> pixels;
};bmp_parser.hpp中定义了BMP Parser返回的数据结构,下面会解析各项的获取。
contentStart
颜色数组的起始地址存储在BMP二进制流0x0A开始的4个字节,对应程序里面的实现是,getSubVector用于进行字节流切割,toNumber是将字节集合按小端序进行解析
// bmp_parser.cpp
size_t getBmpContentStart (const std::vector<u_char>& bmpData) {
std::vector<u_char> chars = getSubVector(bmpData, 0x0a, 0x0a + 4);
return toNumber(chars);
}content
得到contentStart后,就可以根据对应的偏移量,一直切割到整个二进制文件流结尾,获取BMP到内容区
// 获取内容区
std::vector<u_char> getContent (const std::vector<u_char>& bmpData, size_t contentStart) {
return getSubVector(bmpData, contentStart, bmpData.size());
}compression & width & height & deep
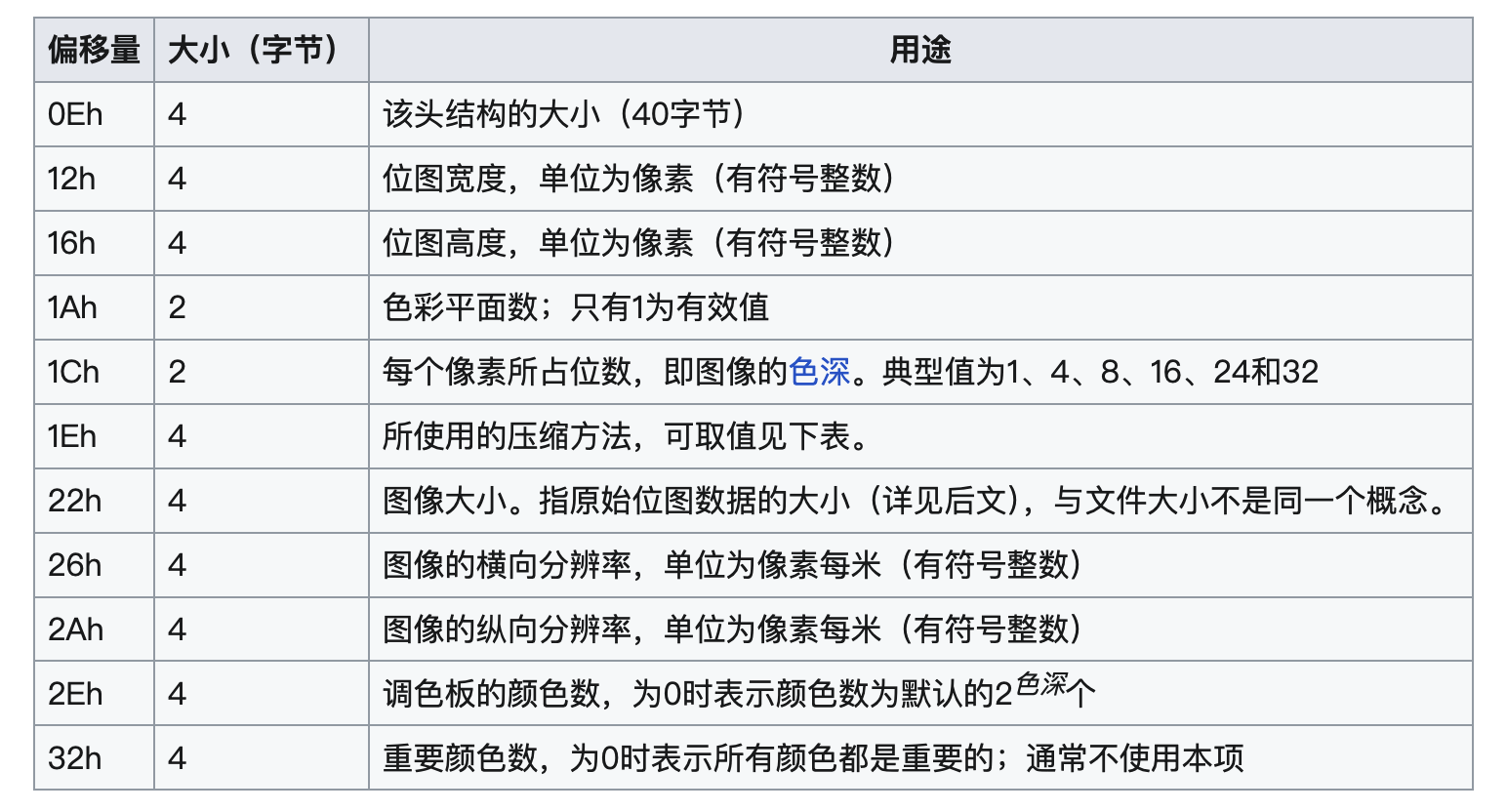 从上面可以看出0xIE开始4个字节存储压缩方式,0x12开始4个字节存储图片宽度,0x16开始4个字节存储图片高度,0x1C开始4个字节存储图片的色深。
从上面可以看出0xIE开始4个字节存储压缩方式,0x12开始4个字节存储图片宽度,0x16开始4个字节存储图片高度,0x1C开始4个字节存储图片的色深。
deep
色深,代表使用多少bit来表示一个颜色数据,色深有两个,一个是BMP文件里面描述的色深0x1C开始4个字节获取,根据称为deepFormat,而还有一个色深,是直接根据 内容区长度/(图片宽度*图片高度),称为deepContent。
// 获取内容区色深
size_t getDeepContent (const std::vector<u_char>& content, size_t width, size_t height) {
size_t contentLen = content.size();
size_t countPixels = width * height;
size_t bitsOneByte = 8;
return contentLen / countPixels * bitsOneByte;
}但是这两个可能都不是最终色深,最终色深根据下面的逻辑进行获取
size_t getDeep (size_t deepContent, size_t deepFormat) {
if (deepContent > 8 || deepContent <= 16) {
return deepFormat;
} else {
return deepContent;
}
}4bit
std::vector<u_char> l;
for (const u_char c : content) {
l.push_back(c >> 4);
l.push_back(c & 0x0F);
}
std::vector<std::vector<u_char>> r;
for (const u_char c : l) {
r.push_back(palette[c]);
}
return r;单个字节会拆分成两个4bit的索引,从调色板(下面会说明)中获取最终的颜色。
8bit
std::vector<u_char> l;
for (const u_char c : content) {
l.push_back(c >> 4);
l.push_back(c & 0x0F);
}
std::vector<std::vector<u_char>> r;
for (const u_char c : l) {
r.push_back(palette[c]);
}
return r;一个字节代表一个索引,同样从调色板中获取最终颜色。
16bit
目前还没遇到真正色深是16bit,测试样本中的16bit最终色深是4bit。
24bit
由于BMP没有透明度,所以24bit就可以代表完整的rbg。
32bit
同样代表完整rgb,最后一个字节无意义。
palette
调色板是一个颜色集合,支持下标索引,用于4bit,8bit色深得到索引后,在调色板获取最终的颜色。调色板里单个颜色长度4字节,调色板起始偏移量是DIB头的结束,调色板总长度存储在0x2E开始4个字节内。
/**
* 返回格式为[[b, g, r, x], ....],x位无意义,标准bmp不支持透明度
*/
std::vector<std::vector<u_char>> getPalette (const std::vector<u_char>& bmpData, size_t sizeDIB, size_t deep) {
std::vector<std::vector<u_char>> r;
if (deep == 4 || deep == 8) {
// 调色板一个色为4个字节
size_t lenBytesOneColor = 4;
size_t lenPalette = getLenPalette(bmpData, deep);
// 一般来说调色板的开始是DIB头的结束,0x0e是DIB头的开始
size_t start = 0x0e + sizeDIB;
size_t end = start + lenPalette * lenBytesOneColor;
std::vector<u_char> l = getSubVector(bmpData, start, end);
std::vector<std::vector<u_char>> chunks = chunkList<u_char>(l, lenBytesOneColor);
for (const std::vector<u_char> chunk : chunks) {
r.push_back(chunk);
}
return r;
}
return r;
}内容区修复
内容区存储的是颜色数据/调色板索引,当内容区色深比最终色深大的时候,代表内容区里面有多余的数据,需要进行去除,多余的字节的去除方法是,算出真正内容区的字节长度,减去当前内容区的字节长度,将内容区分成两半,去除内容区结尾的多余数据。
std::vector<u_char> fixContent (const std::vector<u_char>& content, const size_t deep, const size_t deepFormat, const size_t width, const size_t height) {
if (deep > 8 && deep <= 16 && deep != deepFormat) {
size_t pixelsCount = width * height;
float lenBytesOnePixel = static_cast<float>(deepFormat) / 8;
size_t lenBytesNeed = static_cast<size_t>(std::floor(lenBytesOnePixel * pixelsCount));
size_t lenC = content.size();
size_t lenDiff = lenC - lenBytesNeed;
lenDiff = lenDiff / 2;
std::vector<std::vector<u_char>> contentChunk = chunkList<u_char>(content, lenC / 2);
std::vector<u_char> r;
for (const std::vector<u_char> c : contentChunk) {
std::vector<u_char> contentCut(c.begin(), c.begin() + (c.size() - lenDiff));
r.insert(r.end(), contentCut.begin(), contentCut.end());
}
return r;
} else {
return content;
}
}渲染
最终得到可以直接用于渲染的颜色数据,从下到上,从左到右进行渲染。
// bmp像素转SFML像素
sf::VertexArray points(sf::Points);
for (size_t i = 0; i < bmp.pixels.size(); ++i) {
std::vector<u_char> pixel = bmp.pixels[i];
u_char r = pixel[2];
u_char g = pixel[1];
u_char b = pixel[0];
// 渲染顺序:从下到上,从左到右
size_t x = i % bmp.width + 1;
size_t y = bmp.height - i / bmp.width;
points.append(sf::Vertex(sf::Vector2f(x, y), sf::Color(r, g, b)));
}